Enabling Distributed Training at the Edge with Namla
Published on April 16, 2025

Distributed training on edge devices enables machine learning models to be trained closer to data sources, reducing latency and bandwidth usage. This approach is particularly beneficial in scenarios with limited connectivity or strict data privacy requirements. Namla's Platform (PF) offers robust tools for orchestrating such distributed training across edge environments
Overview of Distributed Training on the Edge
Edge computing brings data storage and computation closer to the devices that generate it, reducing the risk of bandwidth saturation and improving network latency.
However, edge nodes often have limited resources compared to cloud servers, necessitating the adaptation of AI models to fit these constraints. Techniques such as model pruning and quantization are commonly used to reduce the complexity of AI models, making them more suitable for deployment in edge environments.
Implementing distributed training on edge devices involves partitioning the training workload across multiple devices, each handling a portion of the data. This method leverages the collective computational power of edge devices, enabling efficient training without relying solely on centralized cloud resources.
Preparing the Dataset
For this use case, we utilize a Personal Protective Equipment (PPE) dataset to train a YOLOv5 model. The dataset is downloaded from roboflow, it contains 2640 training samples, 160 validation samples and 25 test samples.
After downloading the dataset, upload it to the device, in our case, it is placed under /opt/namla/ultralytics directory.
Deployment
First, on Namla platform, we have to create an app named distributed-training-master for the master node, and another app named distributed-training-worker for the worker node. The following manifest is used for the deployment:
apiVersion: apps/v1
kind: Deployment
metadata: name: distributed-training-master-pod
labels: app: distributed-training
spec: replicas: 1 selector: matchLabels: app: distributed-training
template: metadata: labels: app: distributed-training
spec: hostNetwork: true containers: - name: distributed-training
image: dustynv/l4t-pytorch:r36.2.0 securityContext: privileged: true ports: - containerPort: 9055 volumeMounts: - mountPath: /dev/shm
name: dshm
- mountPath: /PPE_yolov8
name: dataset-volume
- name: datafile-volume
mountPath: /data.yaml
subPath: data.yaml
- name: script-volume
mountPath: /PPE_yolov8/train.py
subPath: train.py
workingDir: /PPE_yolov8
command: - sh
- -c
args: - |+
pip install --no-cache-dir ultralytics && \
torchrun \
--nproc_per_node=1 \
--nnodes=2 \
--node_rank=0 \
--master_addr=192.168.1.90 \
--master_port=9055 \
train.py \
--model yolov8s.pt \
--data /data.yaml \
--epochs 30 \
--imgsz 416 \
--batch 4 \
--device 0 \
--project /PPE_yolov8/yolo_outputs \
--name my_experiment
env: - name: NCCL_DEBUG
value: INFO
- name: NCCL_P2P_DISABLE
value: "1" - name: NCCL_SOCKET_IFNAME
value: eth1
- name: TORCH_DISTRIBUTED_DEBUG
value: INFO
volumes: - name: dshm
emptyDir: medium: Memory
- name: dataset-volume
hostPath: path: /opt/namla/ultralytics/PPE_yolov8
type: DirectoryOrCreate
- name: datafile-volume
configMap: name: data-file
- name: script-volume
configMap: name: training-script
- name: yolo-code
emptyDir: {}
affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname
operator: In
values: - axiomtek-orin-nx-jp6-id8379
---apiVersion: v1
kind: ConfigMap
metadata: name: data-file
data:
data.yaml: |
path: /PPE_yolov8 # Update with your dataset path train: train # Folder containing training images val: valid # Folder containing validation images test: test
nc: 10 names:
[
"boots",
"gloves",
"helmet",
"helmet on",
"no boots",
"no glove",
"no helmet",
"no vest",
"person",
"vest",
]
---apiVersion: v1
kind: ConfigMap
metadata: name: training-script
data:
train.py: |
import argparse
import os
import torch.distributed as dist
from ultralytics import YOLO
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--model', type=str, default='yolov8s.pt')
parser.add_argument('--data', type=str, default='/data.yaml')
parser.add_argument('--epochs', type=int, default=30)
parser.add_argument('--imgsz', type=int, default=416)
parser.add_argument('--batch', type=int, default=4)
parser.add_argument('--device', type=int, default=0)
parser.add_argument('--project', type=str, default='/tmp/yolo-outputs')
parser.add_argument('--name', type=str, default='exp')
args = parser.parse_args()
# ✅ Initialize process group if running distributed
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
dist.init_process_group(backend='gloo', init_method='env://')
print(f"[Distributed] Rank {os.environ['RANK']} initialized.")
model = YOLO(args.model)
model.train(
data=args.data,
epochs=args.epochs,
imgsz=args.imgsz,
batch=args.batch,
device=args.device,
project=args.project,
name=args.name
)
if __name__ == "__main__":
main()
The above manifest runs the container from NVIDIA’s PyTorch Jetson image that includes GPU-optimized libraries and supports distributed training.
- For the master node, the following command is used to start the training:
torchrun \
--nproc_per_node=1 \
--nnodes=2 \
--node_rank=0 \
--master_addr=192.168.1.90 \
--master_port=9055 \
train.py \
--model yolov8s.pt \
--data /data.yaml \
--epochs 30 \
--imgsz 416 \
--batch 4 \
--device 0 \
--project /PPE_yolov_
--nnodes=2: Distributed training across 2 nodes.--node_rank=0: Marks this as the master node.--master_addr: IP address of the master node.train.py: The training script (injected via ConfigMap).\
- As for the worker node, the following command is used:
torchrun \
--nproc_per_node=1 \
--nnodes=2 \
--node_rank=1 \
--master_addr=192.168.1.90 \
--master_port=9055 \
train.py \
--model yolov8s.pt \
--data /data.yaml \
--epochs 30 \
--imgsz 416 \
--batch 4 \
--device 0 \
--project /PPE_yolov8/yolo_outputs \
--name my_experiment- The ConfigMaps mounted onto the device provide two essential components: data.yaml, which defines the dataset structure and directory paths for training, validation, and testing; and train.py, a custom training script that orchestrates the YOLOv8 training process.
After the training is completed, the resulting model can be found under /yolov5/runs/train/exp/weights on the master machine.
Additionally, the model can be converted to onnx format for better optimization on jetson, use the following command to export the model as onnx:
yolo export model=/PPE_yolov8/yolo_outputs/my_experiment/weights/best.pt format=onnxTo test the model, run the command:
yolo predict model=/PPE_yolov8/yolo_outputs/my_experiment/weights/best.pt source='https://youtu.be/LNwODJXcvt4' imgsz=640Distributed vs local training
The following experiments were conducted using two NVIDIA Jetson devices — one equipped with 16 GB of memory and the other with 8 GB. The training was performed over 30 epochs. The table below compares the training durations for various batch sizes, highlighting the differences between distributed and single-device training setups:
| Time | ||
| Batch size | Distributed training | local training |
| 2 | 59 minutes and 56 seconds | 1 hour, 53 minutes |
| 4 | 34 minutes and 13 seconds | 58 minutes and 5 seconds |
Results for distributed training with batch size of 4:
.png)
Results for training yolov8s on single node wiht 16Gb and batch size of 4:
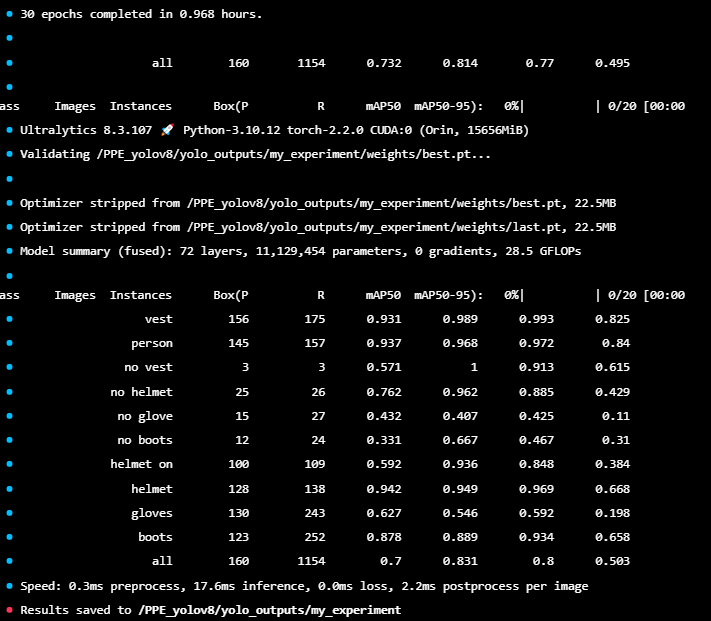
Conclusion
Distributed training significantly reduced training time compared to local training.
For batch size 2, distributed training was nearly 47% faster.
For batch size 4, it was approximately 41% faster.
These results demonstrate that even on resource-constrained devices like Jetson, leveraging multiple nodes in a distributed setup can yield substantial performance improvements, enabling faster experimentation and model iteration.

