Navigating Edge Computing: Latency, Privacy, and Beyond

Published on November 20, 2023

Ready for a demo of
Namla
?
Welcome to the first part of our series on edge computing. In this series, we'll dive deep into the world of edge computing, exploring its complexity, applications, and impact on modern technology. But before we get into all the details, let's start by understanding what edge computing is and why it's so important in today's digital world.
To explain edge computing, we must first delve into the history of computing itself. Starting from the era of mainframes and progressing through the explosive growth of personal computing (PC), the landscape evolved from companies relying on single servers to establishing small server farms, eventually culminating in the creation of what we now know as data centers. Alongside this progression, the emergence of public cloud services took center stage, dominated by the Hyperscalers.
Amidst this ever-changing landscape, an often overlooked yet significant aspect has consistently existed: small-scale, on-premises computing outside the conventional server farms, data centers, and public cloud infrastructure. This concept was previously theorized, and through the analysis of Google Trends data, we can trace its roots back to around 2011. This aspect of computing is what we now refer to as edge computing.
The prevalence of edge computing in various products has led to confusion, so let's clarify its essence. Edge computing involves running applications closer to the objects or humans that consume them. To achieve its benefits, proximity to users must be closer than running applications on a distant public cloud.
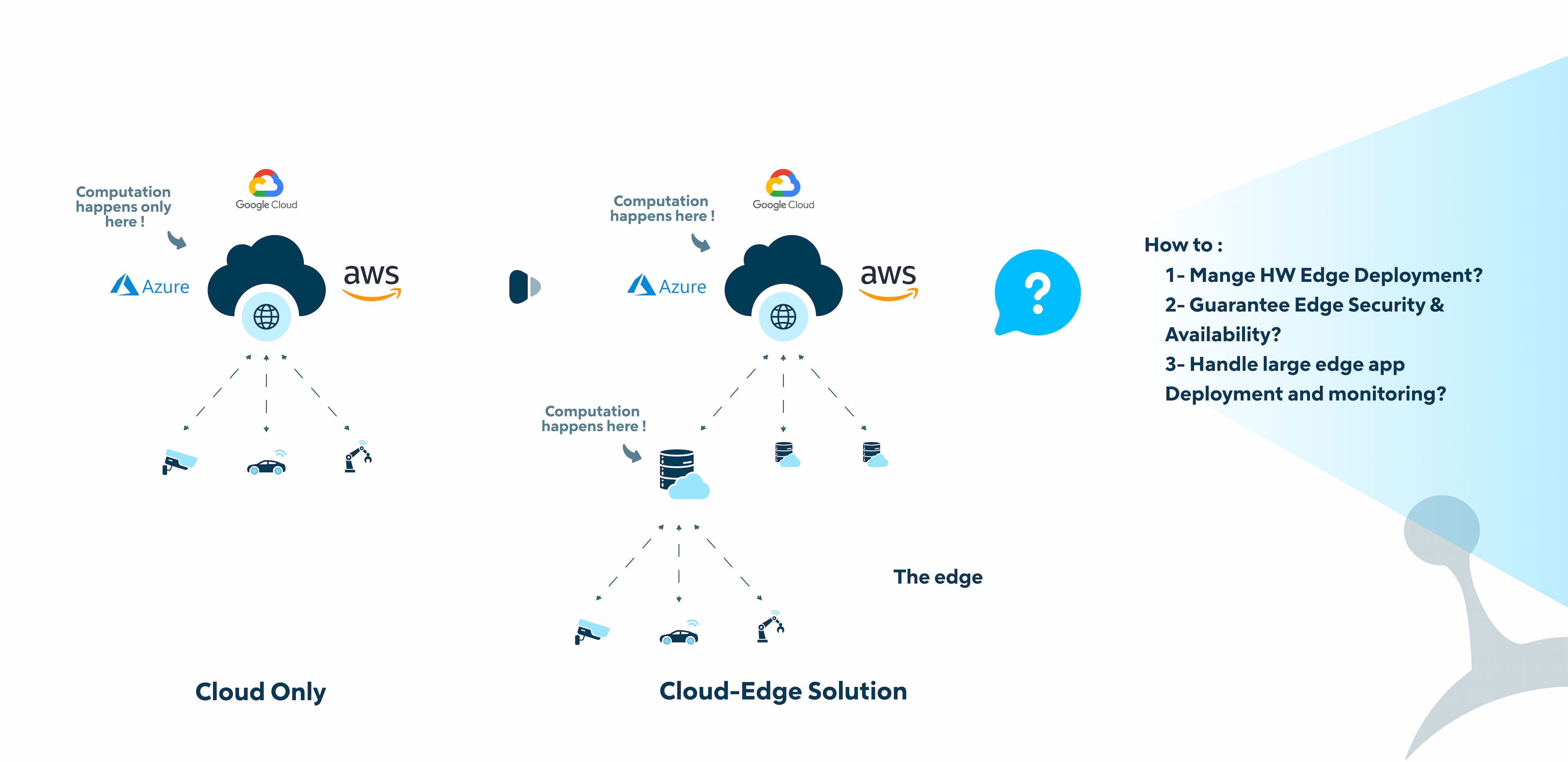
Cloud vs Cloud Edge
Market Study: Edge Computing's Explosive Growth
In 2022, the edge computing market exhibits remarkable potential, with a market size of $15 billion and a serviceable addressable market (SAM) of $45 billion. However, it's the total addressable market of $480 billion that reveals the true potential.
In 2025, bigger changes will be happening. Kubernetes is set to reach $21 billion, while Software-Defined Wide Area Networking (SD-WAN) is projected to soar to $70 billion, but the real game-changer is the expected $500 billion growth in edge verticals. This market change shows how important edge computing is and how it's changing many industries.
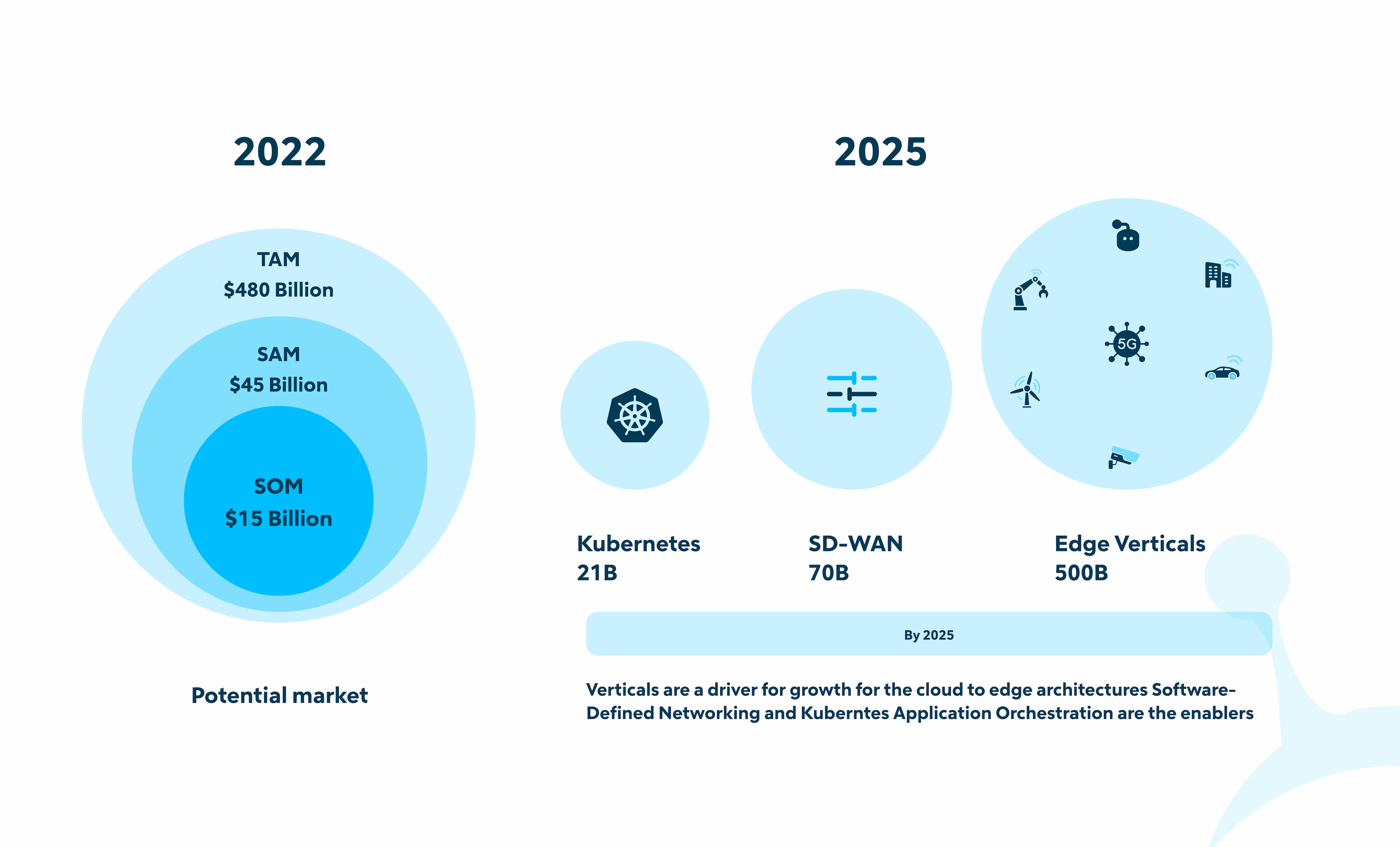
Cloud Edge Potential Market
The Crucial Role of Latency
A significant factor to consider when defining an edge is latency, which refers to the delay in transmitting data from one point to another on the network. One common measure of network latency is the Round-Trip Time (RTT). While there are no fixed standards for a good RTT, it is generally accepted that for cloud services, a good RTT should be under 100 milliseconds, and for edge computing use cases, it should be under 5 milliseconds.
A more practical metric is the application response time. This metric is calculated by summing up the round-trip time of the packet, along with the server response time. The server response time includes the time it takes to execute, generate the response, and send it back to the client.
Latency Across Different Edge Scenarios
Latency values can vary depending on the specific edge deployment and the distance between the user and the computing resources. While exact values may differ in different scenarios, the following latency ranges are common:
- On-Premises Edge
Latency in on-premises edge computing environments is typically very low, ranging from 1 millisecond (1MS) to 5 milliseconds (5MS). This is because the edge infrastructure is physically located closer to the end-users, resulting in minimal transmission delays.
- Data Center Edge or Telecom Edge
In data center edge or telecom edge setups, the latency is slightly higher than on-premises edge but still relatively low. Latency in this scenario can range from 20 milliseconds (20MS) to 50 milliseconds (50MS).
- Cloud
Latency in cloud computing environments can vary based on the geographical location of the cloud data centers and the distance from the users. In general, cloud services aim to keep their response times under 100 milliseconds (100MS) to ensure a smooth user experience.
Additional Drivers of Edge Computing Adoption
Beyond latency, several other compelling factors drive the adoption of edge computing:
- Privacy and Compliance
With concerns about data security and privacy, many companies are hesitant to share sensitive or proprietary information on public clouds, especially with the presence of strict regulations like the US CLOUD Act (insert link) and the European GDPR. Edge computing allows data to be processed and stored locally, reducing the need to transmit sensitive data to distant cloud servers, thereby enhancing data privacy and compliance with regulations.
- Bandwidth Optimization
Transmitting large volumes of raw data or continuous video streams to the cloud can be costly, both in terms of data transfer fees and bandwidth utilization. Edge computing enables data to be processed locally, sending only relevant insights or summarized information to the cloud, optimizing bandwidth usage and reducing data transfer costs.
Autonomy and Business Continuity
Relying solely on a centralized cloud infrastructure can be risky, as any disruption in connectivity could lead to service downtime or loss of access to critical applications. By adopting edge computing, companies can maintain some level of autonomy and continue essential operations even if they experience connectivity issues with the cloud.
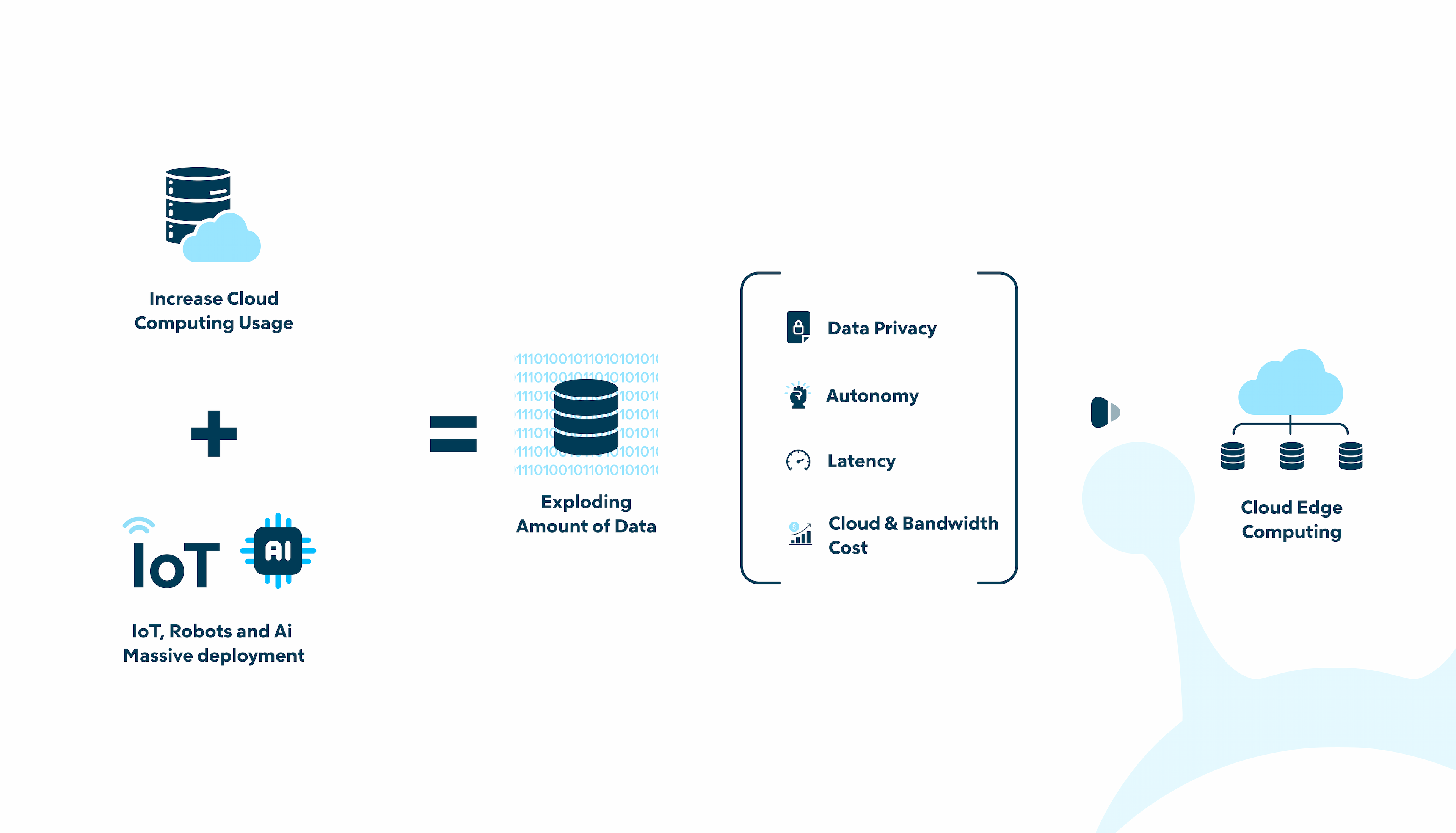
Edge Infrastructure
In our first article about edge computing, we've laid the foundation. We explored its history, talked about why speed matters, and discussed why it's gaining popularity. Next up, we'll dive into how it all works, including the important layers. The future of computing is changing fast at the edge, and we'll keep you updated!